デジタル大辞泉
「クラスター分析」の意味・読み・例文・類語
出典 小学館デジタル大辞泉について 情報 | 凡例
Sponsored by 
クラスターぶんせき
クラスター分析
cluster analysis,clustering
調査対象になっている項目(変数)や個人,組織(個体)などが異質のグループや集団から成立していると考えられるとき,それらを統計的な情報を使って分類する手法を指す。個体を分類する場合には,個体i(=1,…,n)のp変量データxi=[xi1,…,xip]′,または個体間の類似性データに基づいて,類似する個体同士は同じ群(クラスター)に,類似しない対象同士は異なる群に属するような個体の群分け(分類)を見いだす。以下の記述において,変数群を分類する場合には,個体iを変数iと読み替えればよい。クラスター分析は,こうした統計手法の総称名で,階層的クラスター分析と非階層的クラスター分析に大別される。
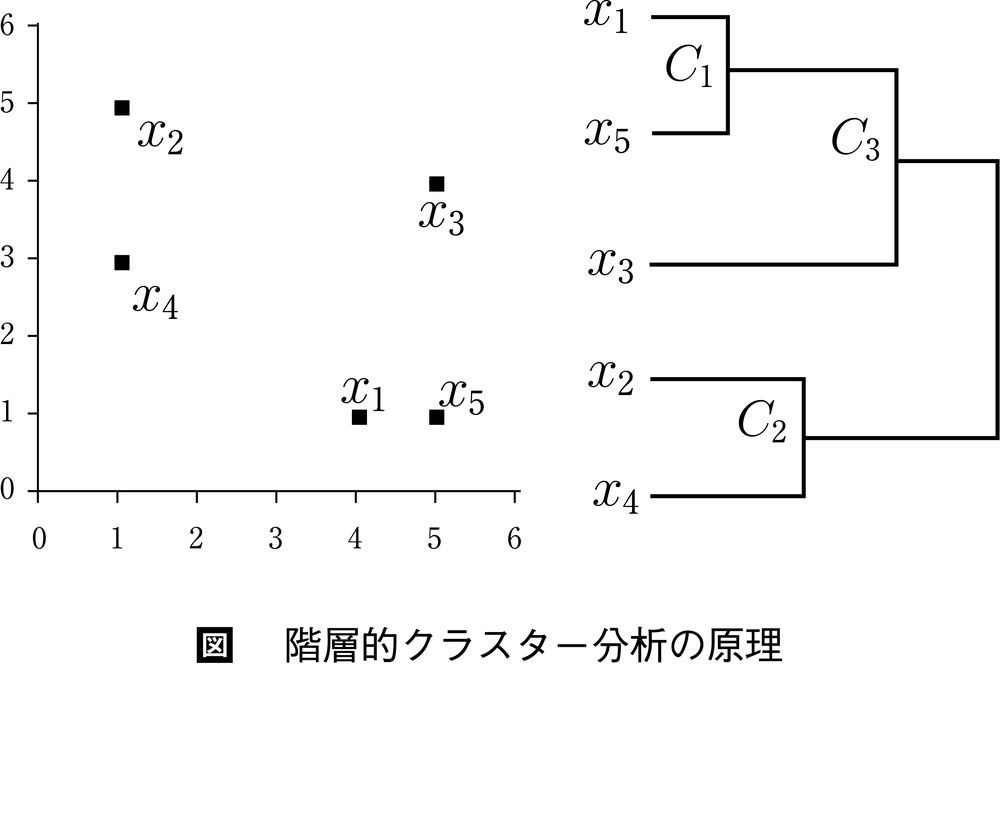
図は階層的クラスター分析hierarchical clusteringの原理を例示する。そのうちの左の図のように散布するデータx1=[4,1]′,x2=[1,5]′,x3=[5,4]′,x4=[1,3]′,x5=[5,1]′の分析結果である右の樹形図(デンドログラム)は,次の3ステップを通して求められる。⑴散布図の5点間の距離を求め,最短のx1とx5を一つの群C1として併合する。この併合を右の樹形図の交わりC1が示す。⑵群C1の代表点を所属個体の点の重心c1=0.5(x1+x5)=[4.5,1]′として,c1,x2,x3,x4間の距離を求め,最短のx2とx4を群C2として併合する。これを右のC2が示す。⑶C2の代表点c2=0.5(x2+x4)とc1とx3の距離を求め,x3とc1が最短であるため,x3をC1に併合する。この併合を右のC3が示す。
以上のステップの⑵,⑶における手順の違いによって,階層的分析はいくつかの下位手法に細分される。その中でも上記の図を用いた説明による手法は重心法centroid methodとよばれ,群と個体,および群間の距離の算出に重心を用いるのが特徴である。ほかに群間距離として,異なる群に属する個体同士の距離の2乗の平均を用いる群平均法group average method,最短距離を用いる最近隣法nearest neighbor method,最長距離を用いる最遠隣法furthest neighbor methodや,群Aと群Bを合併した群内の個体間距離から群A内の個体間距離とB内の個体間距離を減じた値,つまり群の合併に伴う個体間距離の増分を,AとBの距離とするウォード法Ward's methodなどがある。
階層的(逐次的)に個体や群を合併していくのではなく,統計学的に理想的な分類を目的関数によって定義して,それを最適化する方法を非階層的クラスター分析nonhierarchical clusteringと総称する。その代表であるK平均法K-means methodでは,
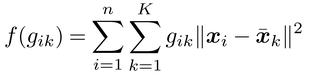
を最小にするgikが求められる。ここで,k(=1,…,K)は群を表わし,gi1,…,giKは,それらの中で個体iが属する群に対応するものだけが1,ほかはすべて0を取るパラメータ,x̄kは群kに所属する個体のデータの平均(重心),∥xi-x̄k∥はxiとx̄kの距離を表わす。目的関数f(gik)を最小にするgikは,各個体とそれを含むクラスターの平均との平方距離の合計が最小となる分類を表わす。
K平均法は,各個体の複数群への所属を認めない方法であるが,それを認める非階層的分析の一つに,計量心理学の分野で開発されたアドクラスADCLUS(additive clustering)がある。これは,iとjの類似性データsijに基づいて,
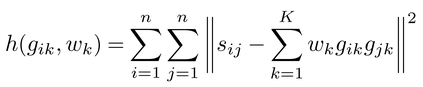
を最小にする1か0のgikと連続量のwk≧0を求める方法であり,そのねらいは,iとjを刺激,群kを特徴kとよび換えるとわかりやすい。すなわち,gikgjk=1となることは両刺激がウェイトwkの特徴kを共有することを表わし,共有特徴のwkの総和によって類似性を記述することをアドクラスはめざしている。 →多変量解析
〔足立 浩平〕
出典 最新 心理学事典最新 心理学事典について 情報
Sponsored by
クラスター分析 (クラスターぶんせき)
cluster analysis
ある集団について各個体の属性あるいは形質データにもとづき似たものどうしをいくつかの群(クラスター)にまとめて類型を作り出す分類手法で,統計的多変量解析法の一つ。数値分類法や自動分類法などともいわれる。クラスターとはブドウの房とか集落の意。クラスター分析が類型を求めるのに対し,判別分析といわれる多変量解析手法はすでにある類型や群に新たな個体を判別する。生物,鉱物の分類をはじめ,ものの分類整理は科学の基本であり,古くからの課題である。日本では古来本草学といわれるものがあった。従来の生物学などでの分類は比較的簡単に観察できる形質に限定して主観的な系統分類が目的であったが,1960年代でのクラスター分析手法の進歩に伴って,個体の特徴を表すあらゆる属性を用いて先入観のない立場からの分類をしたいという要求が高まり,馬の分類,稲の分類といった旧来の課題から,航空衛星写真による土地利用形態分類や地域分類などさかんに利用されてきている。クラスター分析には多様な手法が提案されているが,大きくは階層的手法と非階層的手法に分けられる。階層的手法は動物の進化を樹形図(デンドログラムdendrogram)に表現するようにクラスターの階層構造を求めるもので,群平均法,ウォード法,重心法,最短距離法,最長距離法など一連の手法がよく用いられる。いずれも似たものどうしを順につなげてゆこうという手法であるから,個体間の似ている程度,すなわち類似度,あるいは逆に非類似度や距離を定義した上で,クラスター間の距離をどう測るかを定義する必要がある。それらの定義によって結果として樹形図が異なってくる。非階層的手法の中ではk-means法がよく用いられる。これは,はじめにクラスターの個数kを指定し,いったん適当なk点(個体)をクラスターの核として選び,各点の割付けを行って初期のクラスターを構成する。そして,〈クラスター内ではできるだけばらつかず,クラスターの平均の点はクラスター間で大きくばらつくように〉といった基準を最適化するように各点を順次再割付けを行う手順を反復する。
執筆者:吉沢 正
出典 株式会社平凡社「改訂新版 世界大百科事典」改訂新版 世界大百科事典について 情報
Sponsored by
クラスター分析
くらすたーぶんせき
cluster analysis
さまざまな性質が混在するデータを、客観的な数値基準に従っていくつかの集団(クラスターcluster)に分けて、類型化することにより対象の特性を分析する手法の総称。クラスターとはブドウの房や集落の意。科学的に複数集団に分類するため、先入観や慣例による恣意(しい)的な分類を排除できるという特徴がある。広くマーケティングに活用されており、たとえば消費者が商品を選ぶ際にどのような点を重視するかを調査し、「高級志向派」「堅実派」「流行追求派」といった各クラスター(消費者集団)の特徴ごとに商品開発や販売促進策を進めるという手法がとられる。このほか検査値に基づく疾患の分類、市町村の交通圏・文化圏といった地理的分類による市町村合併や選挙区の区割り、マニフェストによる政党・党派の分類、絵画などの芸術作品や手紙・文章の真贋(しんがん)判定、考古学で発掘された人骨や遺物の分類など幅広い分野で活用されている。
クラスター分析は、グループ分けのための計算手法の違いで、大きく「階層的手法」と「非階層的手法」の二つに分けられる。階層的手法は似たデータどうしをまとめていき、いくつかの集団にわける手法をとる。代表例には、一定の基準に従ってもっとも類似したデータどうしから集めていく「最短距離法」、もっとも遠いデータから集めていく「最長距離法」、クラスター内のデータの平方和を最小にする「ウォード法」などがある。一方、非階層的手法はあらかじめ決めておいたクラスター数にデータを分割していく方法をとり、代表的手法に各クラスターに含まれる各標本点とそのクラスターの重心との近さを計算していく「k平均法(k-means法)」がある。階層的手法は分析結果を樹形図(デンドログラム)に表示できるという特徴があり、樹形図をみながら集団の数を決められるという利点があるが、分類対象が多い場合には計算量が膨大になるという欠点がある。これに対し、非階層的手法は大量のデータ分析に向いているが、クラスター数を任意に設定するため、集団の数によって分析結果が大きく左右されるという欠点がある。
[矢野 武 2016年6月20日]
出典 小学館 日本大百科全書(ニッポニカ)日本大百科全書(ニッポニカ)について 情報 | 凡例
Sponsored by
クラスター分析【cluster analysis】
クラスター(Cluster)はもともとはブドウの房の意味。群れ、集団、集落のこと。住んでいる地域、年令・性別・年収などの人口統計学的データ、趣味・ライフスタイルなどの心理的特徴をベースにして似たようなグループにくくった固まりをクラスターと表現している。共通した特性によって人々や物事をグループに分ける統計的分析手法。有効な分類軸がわからないデータを、自動的に切り口を探し出してくれる。顧客の行動や興味の特性から分類し、例えば、ヤッピー(Yuppies)としてクラスター化し、そのクラスターをターゲットにしてプロモーションコピーやデザインを行う。クラスター分析の前にクラスター・サンプル(ClusterSample)の抽出が必要。顧客リストからテストサンプルを選び出す。例えば、10万人から2つの5000サンプルを選び出す場合、まず10万人をランダムに20グループに分ける。つぎに、その20グループから2つのグループを選択する。もし2つのグループが同じような特徴をもつグループであれば、サンプル間のリスポンスの違いは各グループに送ったプロモーションの違いになる。テスト目的に合わせて、多段階でテストサンプルを抽出する方法。
出典 (株)ジェリコ・コンサルティングDBM用語辞典について 情報
Sponsored by
クラスターぶんせき
クラスター分析
cluster analysis
多変量解析の手法の一つ。データ間の距離を求め,その値に基づき,類似するデータ同士をグループ(クラスター)にまとめていく分析手法。階層的クラスター分析と非階層的クラスター分析に大きく分けられる。階層的クラスター分析は,類似するデータ同士をつなげてデンドログラム(樹形図)を作成する手法。一方,非階層的クラスター分析は,類似するデータ同士をまとめ,指定した数のクラスターに分ける手法である。
執筆者:上田 裕尋
出典 平凡社「最新 地学事典」最新 地学事典について 情報
Sponsored by
岩石学辞典
「クラスター分析」の解説
クラスター分析
すべての変数が同時に測定されている場合の対象となる類似した群を区別する目的で用いられる.この方法を用いたバハマ(Bahama)の炭酸塩堆積物の研究など,様々な研究が行われている[Purdy : 1963, Parks : 1966,Mather : 1969, Pennines & Anderson : 1971, Till : 1974].
出典 朝倉書店岩石学辞典について 情報
Sponsored by
クラスター分析
クラスターぶんせき
cluster analysis
多数の変数あるいは測定対象があるとき,それら相互間の相関係数やそのほか適当な類似度を示す指標を要素とする行列を基礎にして,いくつかのまとまり (クラスター) を発見する方法。因子分析の予備として行う場合が多い。
出典 ブリタニカ国際大百科事典 小項目事典ブリタニカ国際大百科事典 小項目事典について 情報
Sponsored by
クラスター分析
クラスター分析とは、各個体の距離を定義できるデータに基づいて、距離の大小により個体のまとまり(クラスター)を構成する多変量解析の手法のことをいう。
出典 (株)トライベック・ブランド戦略研究所ブランド用語集について 情報
Sponsored by
出典 朝倉書店栄養・生化学辞典について 情報
Sponsored by