
最新 心理学事典 「信頼性」の解説
しんらいせい
信頼性
reliability
【信頼性の推定】 信頼性の推定のために,真の得点が同じで誤差の部分は真の得点と独立であり,その分散の大きさは被験者を通して等しい二つのテストの相関係数が信頼性係数に等しいという事実を利用する。真の得点が同じで,誤差の分散が等しいような二つのテストを平行テストparallel testという。信頼性係数を推定する方法の基本は,二つの平行テストの間の相関係数を得る方法であるといってもよいが,そのための具体的方法にはいくつかの種類がある。すなわち,
⑴平行テスト法parallel test estimation method 二つのテストを平行テストになるように開発し,適切なサンプルに実施して相関係数を得る。この方法は,テストを作るための労力が大きく,しばしば実現が困難である。以下の方法は,平行テストを二つ作る方法より簡便である。
⑵再テスト法test-retest estimation method 同じテストを2回実施して,その二つの結果の相関係数を得る。これは,わかりやすい方法であるが,1回目のテストの結果が2回目のテストに影響を与えないことが前提である。たとえば,1回目のテストの答えを記憶していることが有利な影響を与える場合や,1回目の受験によって,テスト内容に関して学習できる場合には,この2回のテストは平行テストであるとはいえない。このような欠点はあるが,再テスト法は,テスト得点が時間の経過によってどの程度の変動を生じるか,すなわち時間的安定性を評価できる利点がある。
⑶折半法split-half estimation method テストを構成する項目を二つの平行テストになるように,二つの等質な群に分け,その間の相関係数を計算する。ただし,この相関係数は,二つに分けられたテストの信頼係数であり,もともとのテストの信頼性係数は,スピアマン-ブラウンの公式によって復元される必要がある。すなわち折半されたテスト間の相関係数をrhとするとき,信頼性係数rは,
r=
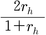
となる。とくに,項目の並び方に特段の規則性がない場合に,奇数番目の項目と偶数番目の項目それぞれの合計を別の二つのテストとみなすことがある。折半法は二つの平行テストに分けたが,三つや四つ,あるいはそれ以上の平行テストに分けることも可能である。n個の部分テストに分けた場合に,もともとのテストの信頼性係数は,それぞれの部分テスト間の相関が同じであるとき(rpとおく),
r=
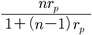
によって得られる。この方法は,先に説明した方法の一般化であり,スピアマン-ブラウン21の方法Spearman-Brown formula 21とよばれる。
テストをいくつかの平行テストに分けることは可能であるが,可能ではあっても現実には難しい。平行テストではなくても,いくつかの条件を満たせば信頼性係数の推定を行なうことができる。平行テストの厳密性を一般化した仮定の代表的なものは,タウ線形とよばれる仮定と,本質的タウ線形と呼ばれる仮定である。タウ線形の仮定は,部分テストjの真の得点(τj)とテストkの真の得点(τk)の間に,
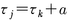
という関係がある場合をいう。
本質的タウ線形の仮定は二つのテストの間の関係をさらに拡張し,
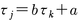
というように,二つの真の得点間に線形関係が成立する場合を指す。部分テストが,本質的タウの仮定を満たす場合に,信頼性係数の推定値を与えるのが,クロンバックのα係数Cronbach's α coefficientである。この係数は,本質的タウの仮定を満たさないときには,信頼性の推定値としては低めの値を与えることが多い。その意味では,クロンバックのα係数は,信頼性係数の評価として保守的で慎重な推定値であるといえる。
本質的タウの仮定よりも平行性の要件をさらに緩め,二つのテストが共通の因子によって説明されるという仮定をおくことがある。これは因子分析モデルにほかならない。この定義に従ってどの程度の信頼性をテストがもつかについては,因子分析の共通性の推定値が指標になる。すなわち共通性が大きいほど,信頼性が高いということになる。α係数も因子分析における共通性も,時間的に安定しているかどうかの意味での信頼性の評価値にはなりえず,テストの等質性の指標である。
【測定の標準誤差standard error for measurement】 テストの信頼性を示す指標として,信頼性係数を中心として説明してきたが,信頼性を示すために,誤差の標準偏差を用いることがある。これを測定の標準誤差という。標準誤差は,推定値や予測値などの統計量の標準偏差を示す用語でもあるので,差異化するためにとくに「測定の標準誤差」という。ただし,単に標準誤差とよばれることもある。測定の標準誤差は,各被験者に対して一定であることを仮定している。言い換えれば,どのような真の値に対応する測定の標準誤差も同じであることを仮定している。
一方,古典的テスト理論に対して,現代的テスト理論とも称される項目反応理論を利用すれば,さまざまな真の得点のそれぞれを所与として測定の標準誤差を推定することができる。
【一般化可能性generalizability】 一般化可能性とは,どの程度の範囲内で安全性を保つかを示す概念である。統計学的には,真の得点のモデルと分散分析モデルは類似したモデルである。すなわち真の得点のモデルは,分散分析の一元配置モデルと同じであり,意味のあるパラメータは,各個人ごとの真の得点である。分散分析モデルの文脈においては,信頼性係数の推定の問題は,単純な測定モデル(一元配置的)の分散の推定の問題である。個人iに対するk回目の繰り返しにおける測定値xは真の得点τと誤差εに分け,次のように書くことができる。
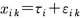
上の式のモデルにおいて,τiとεikの分散を推定してσ2x=σ2τ+σ2εという関係を利用して,r=σ2τ/σ2xを計算する。ところで,分散分析が用いられる実験計画法において,複数の要因が関与する場合があるように,テスト得点のばらつきに影響する要因が個人の真の得点だけではなく,ほかにも複数の要因があるときがある。たとえば,論述試験に対して,複数の評定者がおり,それぞれの評定者によって評価が違うとすると,被験者iを評定者jが採点したk番目の結果xijkは,
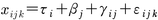 となる(ここで,βjは評定者の効果。γijは,個人と評定者との交互作用を示す)。信頼性は,評定者の偏りを残差とみなすならば,二元配置分散分析によって,分散成分を推定し,xの分散のうち,τの分散とxの分散の比を取って,信頼性係数の推定値とする。真の得点を期待値として定義したが,この期待値は,同じ被験者に対して同じ条件における繰り返しにおける平均である。しかし,条件が異なると期待値も異なる。先述の例では,被験者の真の得点以外に安定して得られる意味のあるパラメータとして評定者を想定したが,そのほかの要因も想定できる。適切な分散分析モデルを仮定し,想定したパラメータのうち,真の得点とみなすべきパラメータの和の分散が,テスト得点の分散のうちどの程度を説明するかを問う手法を一般化可能性の理論とよぶ。単純な信頼性係数の推定の場合よりも,テスト得点がどのような状況で使われるのかに対応して実際的なテスト作製のために有用な情報となる。 →項目反応理論 →古典的テスト理論 →妥当性
となる(ここで,βjは評定者の効果。γijは,個人と評定者との交互作用を示す)。信頼性は,評定者の偏りを残差とみなすならば,二元配置分散分析によって,分散成分を推定し,xの分散のうち,τの分散とxの分散の比を取って,信頼性係数の推定値とする。真の得点を期待値として定義したが,この期待値は,同じ被験者に対して同じ条件における繰り返しにおける平均である。しかし,条件が異なると期待値も異なる。先述の例では,被験者の真の得点以外に安定して得られる意味のあるパラメータとして評定者を想定したが,そのほかの要因も想定できる。適切な分散分析モデルを仮定し,想定したパラメータのうち,真の得点とみなすべきパラメータの和の分散が,テスト得点の分散のうちどの程度を説明するかを問う手法を一般化可能性の理論とよぶ。単純な信頼性係数の推定の場合よりも,テスト得点がどのような状況で使われるのかに対応して実際的なテスト作製のために有用な情報となる。 →項目反応理論 →古典的テスト理論 →妥当性〔繁桝 算男〕
出典 最新 心理学事典最新 心理学事典について 情報
Sponsored by ![]()