
デジタル大辞泉 「回帰分析」の意味・読み・例文・類語
かいき‐ぶんせき〔クワイキ‐〕【回帰分析】
Sponserd by ![]()
Sponserd by ![]()

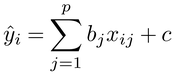
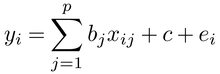
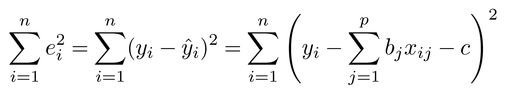
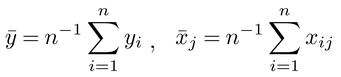


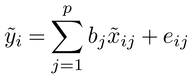
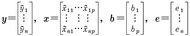
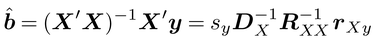


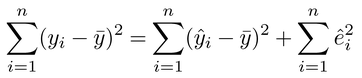
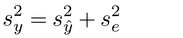
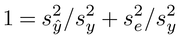




出典 最新 心理学事典最新 心理学事典について 情報
Sponserd by ![]()
ある変数の動きが、他のどのような変数を原因としておこされるものであるか、その影響力はどれほどのものであるか、その変動全体のどれほどの部分がそれらの他の変数によって説明されるのかなどの問題を、統計的手法を用いて数量的に解析すること。
[高島 忠]
いま、ある変数Yがk個の他の変数X1、X2、……、Xkの影響を受けて変動すると考えられるとき、その関係は、a0、a1、a2、……、akを定数として
Y=a0+a1X1+a2X2+……+akXk+V
と表される。ここで、Vはこの関係式に採用されたk個の変数以外の要因からくるYへの影響を集約して表現する変数であって、その値は、なんらかの確率的な法則に従って発生するものと考えられる。X1、X2、……、Xkは説明変数、Yは被説明変数、そしてVは確率攪乱(かくらん)項とそれぞれよばれる。
以下、取扱いを簡単にするために、説明変数が1個である場合について述べよう。Xがx1の値のときYはy1であり、x2のときy2であるというように、XとYに関して対応するデータをn組とする(観測する)。そして、それぞれの場合におけるX以外の要因の効果を表すもの、つまり、確率攪乱項をv1、v2、……、vnとすると、
yi=a+bxi+vi (i=1,2,……,n)
となる。これは、もっとも簡単な線型回帰モデルである。
[高島 忠]
n組のデータ(x1,y1),(x2,y2),……,(xn,yn)から未知の係数a、bを求めるには、最小二乗法が用いられる。それは、この方法によって得られるa、bの推定量â、 が、確率攪乱項viに関するある仮定の下で、推定式として統計的に望ましい性質を備えているからである。
が、確率攪乱項viに関するある仮定の下で、推定式として統計的に望ましい性質を備えているからである。
推定量â、を用いて計算されるyiの値と実際の観測値yiとの誤差をeiとすると、â、は、その誤差の2乗和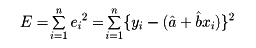
が最小になるように求められる。すなわち、Eが極値をとる条件として、âおよびでそれぞれ偏微分したものを0とおいて、
という連立方程式が得られる。これは、線型回帰モデルの未知のパラメータa、bの値を推定するための正規方程式とよばれる。これを解くことによって、âとは次のように得られる。

ここで、Σはすべてiについての1からnまでの和を表す。
[高島 忠]
このようにして求められる回帰係数については、正規方程式の第1式から、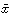 、
、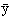 をそれぞれxiおよびyiについての平均値として
をそれぞれxiおよびyiについての平均値として
=â+
の関係のあることがわかるので、回帰直線は、XおよびYの観測値の各平均値を座標とする点(,)を通る。また、誤差eiの総和は0となるので、観測値を描いたグラフ上で、回帰直線より上方にある観測点から回帰直線までの距離の総和は、下方にある観測点から回帰直線までの距離の総和にかならず等しい。
[高島 忠]
変数yに対する変数xの影響力(説明力)の強さは、回帰直線に対する変数yiのばらつきの大きさによって測られる。
それは、 iを回帰係数を用いたyiの計算値とするとき
iを回帰係数を用いたyiの計算値とするとき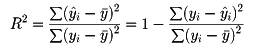
として表され、決定係数とよばれる。
[高島 忠]
『森田優三著『新統計概論』(1974・日本評論社)』▽『J・ジョンストン著、竹内啓他訳『計量経済学の方法』(1975・東洋経済新報社)』
出典 小学館 日本大百科全書(ニッポニカ)日本大百科全書(ニッポニカ)について 情報 | 凡例
Sponserd by ![]()
なんらかの操作や活動の結果を予測したり,その結果の変動を制御したりするための手法で,統計的多変量解析の一つ。操作や活動のデータとそれに対応する結果のデータの組を多数集め,予測の対象とする量(目的変数もしくは従属変数と呼ぶ)の変動を,操作や活動のデータのうちその変動を説明する要因と考えられるデータ(説明変数もしくは独立変数と呼ぶ)によって予測するために,両者の関係を求めることをいう。製鉄所の炉の制御や化学工場での操業条件の決定のための工程解析をはじめ,経済データの分析や予測,心理学や医学など,多くの分野でもっともよく使われる統計的手法である。
身長の高い父親からは身長の高い息子が生まれる傾向(相関関係)がある。x軸に父親の身長,y軸に息子の身長をとり,多くの家族のデータを散布図に表現し,x軸を小区間に分割し,各区間に含まれるyの値を平均し,それらの点をむすぶとほぼ直線になる。ここで,身長の高い父親から生まれた息子の平均身長は父ほど高くなく,身長の低い父親から生まれた息子の平均身長は父ほど低くないという関係がある。F.ゴールトンは1889年この関係を発見し退行と名づけ,直線を退行直線もしくは回帰直線と名づけた。これが回帰という名称の起源である。その後他分野にも適用され,説明変数と目的変数の関係が曲線の場合や一つの目的変数に対応する説明変数が多数ある場合にも回帰分析が行えるようになった。
説明変数が一つのとき単回帰または直線回帰分析,二つ以上のとき重回帰分析ということがある。単回帰分析では,目的変数の第i番目の値をŷi,対応する説明変数の値をxiとすると,直線ŷi=a+bxiを回帰式と呼び,定数項aと偏回帰係数といわれるこう配bをいわゆる最小二乗法で推定する。すなわち,観測値yiと予測値といわれる回帰式上の値yiとの差ri=yi-ŷiを残差といい,その残差の2乗の和(残差平方和)を最小にするaとbを求める。いいかえれば観測値と予測値ができるだけ近くなることが望ましい。そこで,観測値と予測値の相関係数を一般の重回帰分析にも通用するように重相関係数,その2乗を寄与率と呼んで,回帰式の観測値に対するあてはまりのよさを示す指標とする。回帰式としては,ŷi=a+b logxiのようにxiの簡単な変換式を用いたり,ŷi=a+bxi+cxi2のように多項式を用いることもできる。重回帰分析では,説明変数をx,z,……などと書いて,回帰式をŷi=a+bxi+czi……などとする。回帰分析では多数の変数が説明変数の候補と考えられるが,実用上は数個(3~7個,たかだか10個程度)の説明変数を選んであてはまりのよい回帰式がほしい。データの個数としては説明変数の数の10倍ぐらいはあってほしい。
回帰分析を行うときのデータは,よく管理された実験で得られるデータとは限らず,日常の活動の中で記録されたものであることが普通である。そこで,回帰分析を行う人も,その結果を利用する人も,まず,データの質を検討し,あてはめられた回帰式の妥当性を検証することが必要である(そうすることを回帰診断ということもある)。データの質としては,外れ値の有無と共線性を検討する。大部分のデータの変動の範囲に比べて孤立して飛び離れた位置にあるデータを外れ値といい,それは各変数の分布や散布図を見るほかに残差の分布を調べることによって検出される。すべての外れ値が誤ったデータというわけではないが,外れ値の原因を調べたり,その外れ値を除外して回帰式を求めた場合の変化をみることによって価値ある情報が得られることが多い。実際に操業中の工程で観測されたデータはよい製品を作るために管理された状態での値であるから,実験なら説明変数の値を自由に変えられても,実際には説明変数の間に高い相関をもつことが多い。説明変数間に高い相関があることを一般に共線性があるという。そのようなとき推定した回帰式の係数は信頼度の低いものとなり,回帰係数の符号も予想とは逆になることがある。多くの説明変数があるとき,説明変数を増せば寄与率は高くなるが,その回帰式を用いて予測してもかえって誤差は大きくなり,制御に利用しても不安定となる。そこで,いろいろな観点から回帰式の妥当性を比較する基準をつくって適当な説明を選択して回帰式を求める手法が開発されている。それらは変数選択法あるいはモデル選択法と呼ばれ,コンピューターのソフトウェアとしても整備されてきている。最後に得られた回帰式をはじめとする知見は,新たなデータを観測してそのデータを十分に説明するかどうかによって検証することが望ましい。
→相関分析
執筆者:吉沢 正
出典 株式会社平凡社「改訂新版 世界大百科事典」改訂新版 世界大百科事典について 情報
Sponserd by ![]()
出典 (株)アクティブアンドカンパニー人材マネジメント用語集について 情報
Sponserd by ![]()
出典 ブリタニカ国際大百科事典 小項目事典ブリタニカ国際大百科事典 小項目事典について 情報
Sponserd by ![]()
出典 (株)トライベック・ブランド戦略研究所ブランド用語集について 情報
Sponserd by ![]()
Sponserd by ![]()
…一つは経済データを作成する政府系機関等がよく用いるもので,考える変数の原系列を適当な長さの移動平均で割って季節指数を求め,さらにこれを年間平均が100になるように調整したうえで,原系列に適用することによって季節変動を除去した系列が求められる。これに対して,回帰分析を用いる方法も存在する。考えている変数の中・長期的な変動を説明する変数とともに,季節ダミーを回帰式の右辺に導入し,季節変動の部分を後者によってとらえようとするものである。…
※「回帰分析」について言及している用語解説の一部を掲載しています。
出典|株式会社平凡社「世界大百科事典(旧版)」
Sponserd by ![]()
地表近くで見られる蜃気楼(しんきろう)現象の一種。晩春から夏にかけて、よく晴れた日に熱せられた道路のアスファルト面を遠くから視線を低くして見ると、水たまりがあるように見えることがある。これは地面付近の...