
最新 心理学事典 「構造方程式モデル」の解説
こうぞうほうていしきモデル
構造方程式モデル
structural equation model(英),mode`le d'e´quations structurelles(仏),Strukturgleichungsmodelle(独)
【モデルの基本的アイデア】 潜在変数とは,ある程度普遍的な意味をもつ一方で物理量のように正確には定義しにくい概念である構成概念constructの数学的な表現であり,因子分析モデルでは共通因子common factorにあたる。因子分析モデルでは潜在変数が導入されてはいるが,潜在変数から観測変数という一方向の因果しか扱えない。回帰分析を拡張したパス解析path analysisでは,因果の設定は比較的自由に行なえるが,潜在変数を扱うことは想定されていない。一方,構造方程式モデルは,観測変数と潜在変数の間に任意の因果関係を設定できるという柔軟性をもつ。
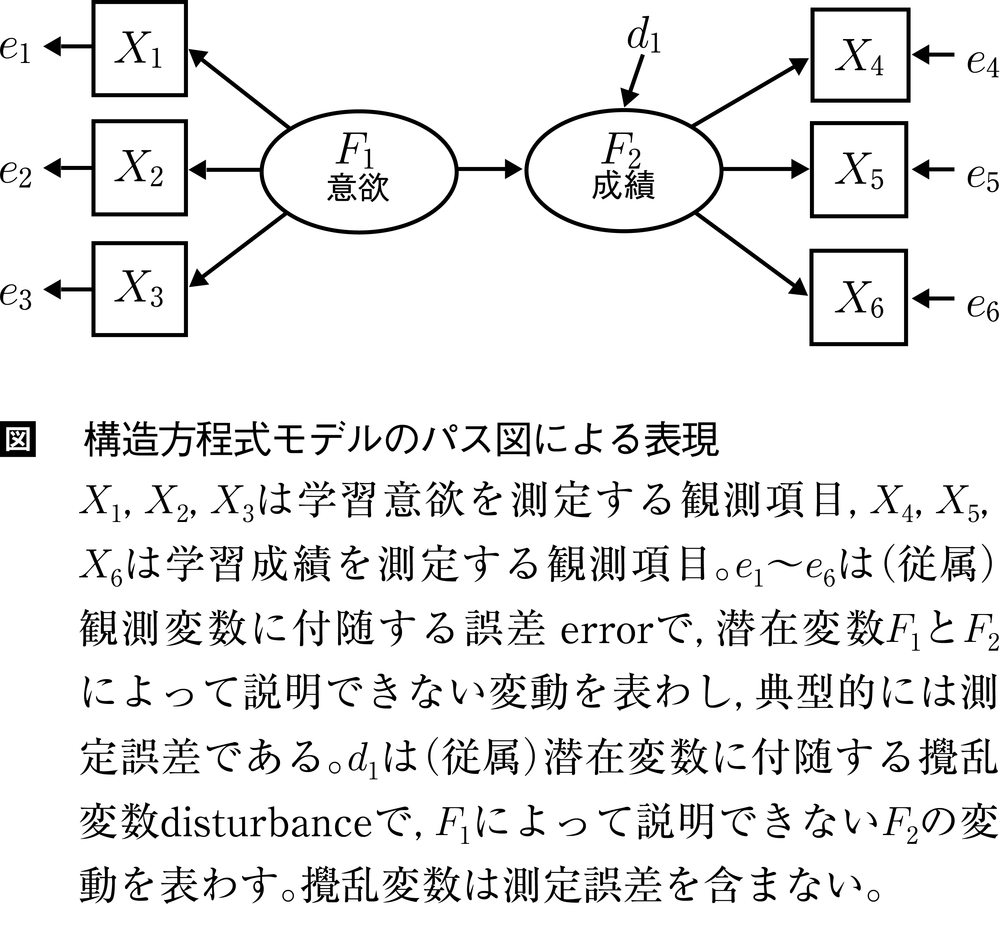
図は典型的な構造方程式モデルである。このような因果図をパス図path diagramとよんでいる。観測変数は四角,潜在変数は楕円で囲んで区別するのが通例で,因果関係は単方向,相関関係は双方向の矢印で描く。単方向の矢印を受ける変数(従属変数)には,必ず誤差(攪乱)変数が付属する。誤差を明示的に分離することによって,観測変数間の相関分析や回帰分析では不可避であった推定の希薄化estimation attenuationの問題が発生せず,誤差を含まない真の変数間の関係を推定できる。推定の希薄化とは,測定誤差のために計算される相関係数や回帰係数などの推定値が,本来の値より低くなることを指す。正規分布に基づく典型的なモデルでは,推定する母数(パラメータ)は回帰係数(因子負荷量・パス係数),独立変数の分散と共分散の3種類である。推定は,⑴仮説モデルに基づき構造方程式を作成,⑵モデルの分散・共分散を母数で構造化,⑶構造が標本分散・共分散に最も近づくように母数を推定,という手続きで行なわれる。モデル構築の際は,推定値を一意に求めることができる識別性identifiabilityを確保する必要がある。
【構造方程式モデルの利点】 ある心理過程や社会現象の実証では,それらの一部を切り取ったデータから,因果関係の方向の同定とその大きさの推定が行なわれることが多い。これに構造方程式モデルによる分析を適用することの最大の利点は,先に述べたモデル構築の自由度の高さに加えて,データに対するモデルの当てはまりの良さを評価できることであろう。
評価にはカイ2乗値(適合度検定)や各種の適合度指標goodness-of-fit indexが用いられる。分析の出発点となるモデルは研究仮説に基づいて構成されるものであり,変数間の関係を想定する際になんら制約はない。その反面,そのモデルがデータの性質を十分に表現しているという保証はない。モデルの母数が問題なく推定できても,モデル自体の良さ,すなわちデータとモデルの乖離が十分小さいかどうかは未知である。モデルの良さの客観的指標が適合度であり,パス図に基づいて計算される観測変数間の分散・共分散と,データから計算される分散・共分散の食い違いの程度を評価することによって算出される。代表的なものに,データとモデルの距離をカイ2乗分布と比較できるよう変換した統計量であるカイ2乗値(小さい方がよい),独立モデル(観測変数間にパスをいっさい引かないモデル)と分析モデルの双方の自由度を考慮したうえで乖離度を比較するCFI(comparative fit index),回帰分析における決定係数と自由度調整済み決定係数からヒントを得たGFI(goodness-of-fit index)とAGFI(adjusted goodness-of-fit index:大きい方がよい),1自由度当たりの乖離度の大きさを評価するRMSEA(root mean squared error to approximation:小さい方がよい)などがある。
同じ変数群で構成される複数個のモデルの優劣比較のための指標が情報量規準information criterionで,たとえば赤池情報量規準Akaike's information criterion(AIC)がある。モデルに新たなパスを引いて母数を増やすと,カイ2乗値は必ず小さくなる。しかし,パスが多いモデルが必ず良いとは限らない。AICのほか,大標本の場合にやや大きすぎる(母数の数が多く,自由度が小さい)モデルを選択してしまうというAICの欠点を補った規準として,ベイズ情報量規準Bayesian information criterion(BIC)やCAIC(consistent Akaike's information criterion)がある。
ただし,たとえ良好な適合の構造方程式モデルが得られたからといって,それだけをもって心理過程や社会現象における特定の因果関係の存在を立証できたと主張するのは早計である。考慮すべき点として,研究者が設定する任意のモデルと適合度はまったく同じである一方で,変数間の関係は異なる同値モデルequivalent modelが存在する可能性があげられる。同値モデル間では,データの情報だけでは因果と相関や因果の方向といったモデルの違いを区別できない。たとえば,「勉学の意欲がないから成績が下がる(意欲X1→成績X2)」と「成績低下で勉学の意欲がなくなる(成績X2→意欲X1)」とは,X1=β2X2+e1とX2=β1X1+e2が同値になるため,これらのモデルの優劣を決定できない。潜在変数を導入したモデルでも同様で,図のモデルと,因果の方向を逆にした(成績F2→意欲F1)というモデルとは互いに同値モデルであり,両モデルの適合度は一致する。また,構造方程式モデルは非実験データに適用される事例が多いが,非実験データに基づいて因果関係を完全に同定する方法は存在せず,因果に関する強い結論を期待すること自体に無理がある。統計学に基づく分析結果の適切な解釈は,モデルに含まれる変数間の関係に関する実質科学的な知見によって担保されることが必要不可欠である。
構造方程式モデルの一つに複数個の母集団を推測統計学的に比較する多母集団同時分析multi-sample analysisがあり,複数の母集団のデータの構造について,同時に推論することができる。たとえば,いくつかの母集団から得られたデータに基づいて因子分析の結果を比較したいとき,配置不変性(母集団間でモデルが同一)や測定不変性(配置不変かつ母集団間で因子負荷量の値が等しい)などを統計的検定によって検討することができる。
平均構造モデルmean structure modelでは,通常0に固定されている潜在変数の平均を推定することができる。潜在変数の平均の推定は,つねに意味があるわけではないが,多母集団同時分析や縦断的データにおける平均の時間的変化を検証する際などに,重要な情報を与える。また,平均構造のある多母集団同時分析は,欠損値を含むデータの解析にも応用することができる。 →因子分析 →回帰分析
〔狩野 裕・三浦 麻子〕
出典 最新 心理学事典最新 心理学事典について 情報
Sponsored by ![]()