デジタル大辞泉 「分類」の意味・読み・例文・類語
ぶん‐るい【分類】
[類語]類別・仕分け・組み分け・分別・色分け・分ける
Sponsored by ![]()
Sponsored by ![]()
出典 精選版 日本国語大辞典精選版 日本国語大辞典について 情報 | 凡例
Sponsored by ![]()
〈分類〉とは文字どおり,対象を類に従って(似たものをまとめて)分けることであるが,〈類別〉とは違って,全体を共通性に従って大きく分け,分けたものをさらにまた共通性に従って細分し,これ以上分けることのできない個体の一つ手前(種という)まで順次分けていって段階づけ,体系化することをいう。
分類するという営為はおそらく人類の歴史とともに古く,植物や動物にすでに見られるように,自分と同類のもの(とくに異性)とそれ以外のものに分けることが始まりであったと見られる。ついで個体保存に必要なもの(食料など)と有害なもの(敵や毒物など)の区別が意識されたに違いない。こうして生活の必要から環境の諸物を分類していったと思われるのであって,現在でも生活様式の相違によって分類体系は異なっていることが確認される。このように事物を分類して認識することが〈理解〉といわれるのであって,〈分けること〉が〈わかること〉の第一歩であった。〈理解〉を意味する英語のcomprehensionも事物を一定の分類の枠に包摂することからきている。英語には別にunderstandingという語があるが,これは理に従って分解するという意味の〈理解〉よりも,まず原理を打ちたててそこから種まで演繹するという古代ギリシア以来の体系化の仕方を反映している。
分類には,春夏秋冬や幼児,少年,青年,壮年,老年といった時間的なものもあるが,これらは単なる区分であって狭義には分類とはいわない。体系化されていないからである。したがって分類は多く空間的ないし通時的であって,存在物については洋の東西とも天,地,人に分けるのが基本となっている。たいていの神話では,まず天と地が分けられ,ついで人間が登場するという形になっているのである。天では恒星天と日,月,惑星の特殊な動きが注目されて諸天(球)に分けられたが,地は陸と海のほか動物,植物,鉱物ないし生命のあるものとないものという分類がなされた。
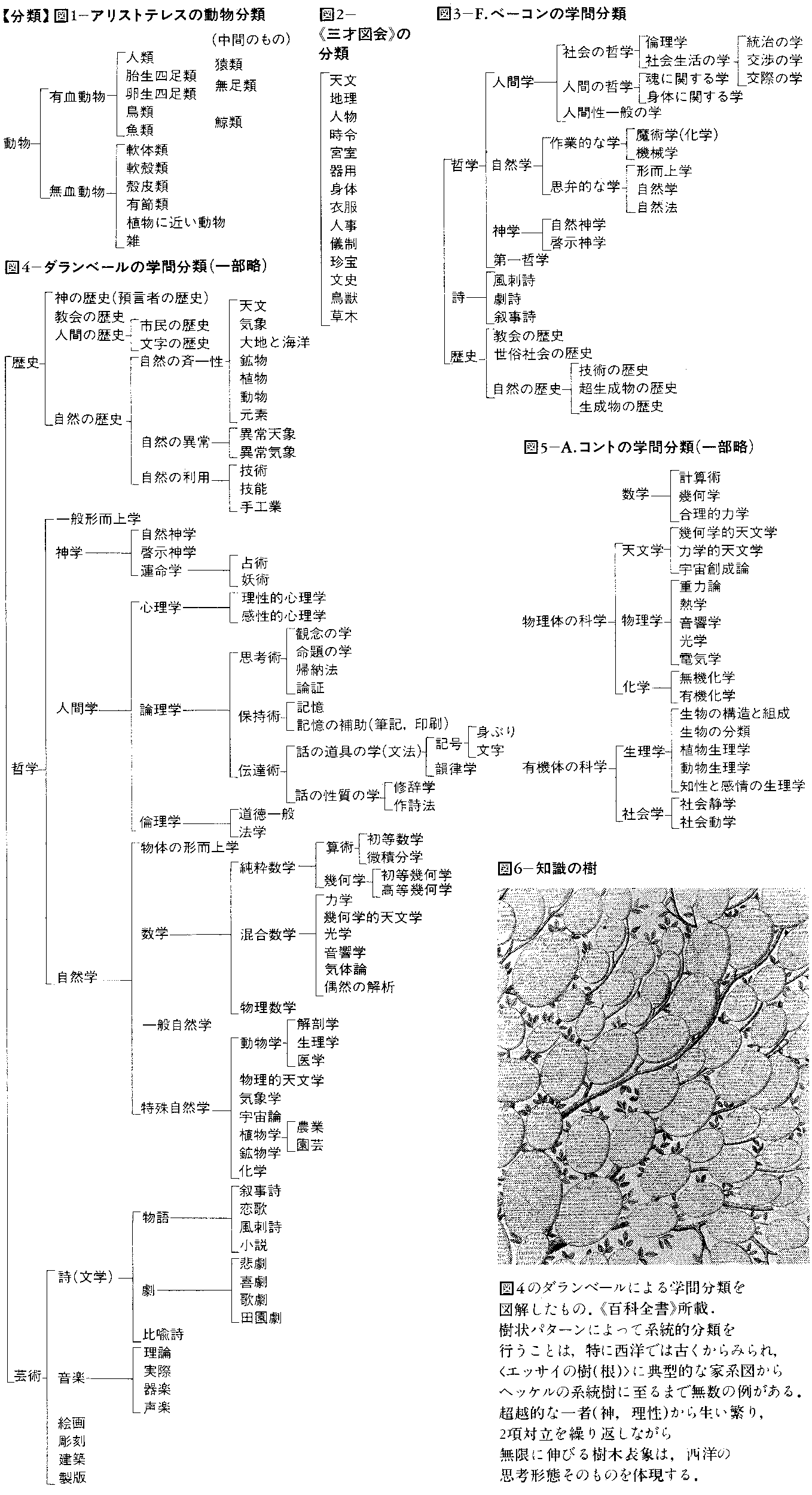
西洋で分類の基礎をつくったのはアリストテレスで,おもに動物について分類体系をつくり(図1),その弟子のテオフラストスが植物分類を試みた。ローマ時代の大プリニウスの《博物誌》は天,地,人にわたっての総括の試みである。インドでは天,地,人を区別せず,パクダ・カッチャーヤナのように地,水,火,風,苦,楽,魂を要素とするような哲学をつくったが,これらは構成要素であって分類とはいえず,普遍者を重んじるインドでは一般に博物学は発達しなかった。中国では,《書経》で五行,五事,八政,五紀,三徳,五福,六極など〈九疇(ちゆう)〉と呼ばれるカテゴリーが展開され,《易経》では陰と陽にもとづく体系がつくられたが,いずれも事物の性質やふるまいを規定するものと考えられ,事物を分類する枠組みとはいいがたい。分類としては《易経》の〈繫辞伝〉に出てくる〈三材〉(天,地,人)や明代にできた博物誌《三才図会》の14門があげられる(図2)。〈門〉は分類の最も大きい枠で,あと〈綱〉〈目〉〈科〉〈属〉〈種〉のほか〈族〉〈系〉〈界〉〈部〉〈略〉なども分類の枠を指す語として用いられた。
学問の分類は,プラトンの弟子のクセノクラテスが論理学,自然学,倫理学の三つに分け,アレクサンドリア時代に学問の分科が進んだので,ローマではこれを学ぶためにウァロが文法,論理学,修辞学,幾何学,算術,天文学,音楽,医学,建築学の9学科に分けた。5世紀にマルティアヌス・カペラが後の二つを落として自由七科ができた。17世紀初頭に新しい学問や技術の発展をふまえてF.ベーコンが新しい分類(図3)を始め,フランスの《百科全書》(図4)に引きつがれたが,19世紀にA.コントが歴史的,論理的順序による分類(図5)を提唱して,これが現在も大学の教科編成や図書の分類に用いられている。劇を喜劇,悲劇,頌歌に分類したのは前3世紀の詩人カリマコスであるが,彼はアレクサンドリアの図書館司書だったので,図書目録のための分類であった。中国では学問の分類も図書の分類によったので,経,史,子,集の〈四部〉や集,六芸,諸子,詩賦,兵書,術数,方技の〈七略〉が用いられた。
語彙の分類としては,すでに古代エジプトやメソポタミアに分類語彙集があり,ローマ時代にもポルクスJulius Polluxがギリシア語の《名前の書(オノマスティコン)》を書いている。これは後2世紀であるが,同じころに中国では許慎が9353字を540部に分類した《説文解字(せつもんかいじ)》を完成した。ヨーロッパでは18世紀前半からこの種の書物が出始めて〈シソーラスthesaurus〉と呼ばれた。英語のシソーラスではロジェPeter Mark Roget(1779-1869)のもの(《英語語句宝典》1852)が有名であり,日本でも国立国語研究所の編集による《分類語彙表》(1964)が出ている。
19世紀に入って統計が各方面で行われるようになってから分類は新しい局面を迎えた。統計をとる場合には類を同じくするものでなければ意味がないので,〈標識〉に従って種々の類別が行われるが,規模が大きくなると全体について就業者と非就業者,男と女などの分類がなされるようになり,継続的に統計をとって動態を見るために産業分類や病因分類のような国際的な標準分類もつくられるようになった。統計は一定の目的のためのものであるから産業分類や職業分類も種々あり,会計の費目分類も種々ある。統計用に限らず,一般に分類は便宜的なものであるから,綱目のどれにも属さない〈その他〉(〈雑〉)の部分が必要である。芸術においても同様で,学問の分類も工学が成立し,境界領域の学際的研究が進んでいる現状の中で,既成の分類の枠に入らないものが出ており,各方面で新しい分類が要請されつつある。建築分類(SFB)や高分子の分類,紙パルプの分類,酵素の分類,水質の分類など種々の試みがあるのはその現れであり,最近は電算機処理のためコード化されることが多い。
→カテゴリー →分類学
執筆者:坂本 賢三
人間は〈分類する動物〉である。しかし,人間が〈分類する動物〉であるというとき,分類されたものに名を与え,そして分類体系をつくりあげることを意味している。実際,あるものに名を与えるということはすでに分類していることなのである。たとえば,〈うどん〉という語は〈きしめん〉でも〈そば〉でもない〈めんるい〉のひとつとしてわれわれは〈うどん〉といっている。また,もう少し抽象的な例をあげれば,〈悲しい〉という語は〈喜び〉や〈怒り〉〈苦しい〉〈恐れ〉などと区別される〈感情〉のひとつとして用いている。このように具体的・抽象的にかかわらず,どのような語も分類体系の網目からはずれて存在することはできない。
どのような分類体系をつくりあげるか,またどのような分類単位に命名するかは文化によって異なる。オーストラリアの原住民は一般によく発達した親族名称の体系をもっているし,インドネシアの北ハルマヘラの文化では方位と距離に関する空間の分類体系に精緻さを見る。また,ミクロネシアに見られる天文,航海に関する分類体系もひじょうに発達したものである。
このような分類体系をつくりあげることを可能にしたのは,人間が言葉を使用しはじめたからである。そして,そのことが人間の分類を他の動物の分類とは比較できないほどに発達させたのである。
先の〈うどん〉を例にとると,この語はこれ以上に分けることのできない語であることに気づく。〈う〉でも〈うど〉〈どん〉でも意味をなさない。〈うどん〉という語になってはじめて意味をもつ。このような語を単一語彙という。これに対して〈てんぷらうどん〉という語は,〈てんぷら〉と〈うどん〉という二つの語に分けることができる。このような語を合成語彙という。そして単なる〈うどん〉と〈てんぷらうどん〉とを比べると,後者は前者の一種であることは明瞭であろう。すなわち,〈うどん〉は〈てんぷらうどん〉の上位分類単位である。そして〈てんぷらうどん〉に並ぶものには〈きつねうどん〉や〈月見うどん〉といったものがある。
ここまで述べると,人間の分類体系の形成の仕方のひとつの特徴が明瞭になってくる。すなわち,分類体系の形式では単一語彙が分類の上位概念となり,合成語彙は下位概念となる。さらに,分類の発達の仕方を考えると,先に単一語彙が出現し,その後に合成語彙が現れる。そしてこの規則性はどの言語においても認められる。
しかし,現実の分類体系はこのように単純なものではない。さらに複雑な体系が形成されるには,もうひとつの異なった発展の形式が必要である。先の例を続けると,〈うどん〉の上位概念として〈めん〉あるいは〈めんるい〉という語がある。ここには単一語彙~単一語彙という連鎖が見られ,先の連鎖とは異なった様相を呈している。ところで,〈めん〉の下位で〈うどん〉と並ぶものを見てみると,〈そば〉〈中華そば〉〈そうめん〉〈きしめん〉などがある。これらのうち,〈中華そば〉を除けば現在のわれわれにとってはいずれも単一語彙である。しかし,〈そうめん〉と〈きしめん〉には〈めん〉という共通した語彙要素が認められる。それは,かつてはこれらの語が〈めん〉の下位分類単位として認識されていたことによる。そこでは単一語彙~合成語彙という連鎖が見られ,先の規則性と一致する。
実はこのような現象は歴史が関係している。おそらく,〈うどん〉が〈めん〉よりも先に日本に伝えられ,その後〈めん〉という概念を受けとった。〈そうめん〉や〈きしめん〉は〈めん〉という概念を受けとった後につくりだされたものであり,そのため,〈めん〉の下位に単一語彙と合成語彙の2種が出現するようになったのであろう。このように分類体系はつねに歴史的な産物であることを了解しておかなければならない。現在では,〈スパゲッティ〉や〈マカロニ〉も〈めん〉の中に含まれていることであろう。
ここで重要なことは〈うどん〉と〈めん〉の結合である。それは〈うどん〉が〈めん〉の一種であると認め,その下位概念に組み入れたことである。そして,〈めん〉~〈そうめん〉の連鎖と〈うどん〉~〈きつねうどん〉の連鎖の再編成がそこに起きたことである。一般に単一語彙~単一語彙の連鎖はもともとは異なった意味領域に属するものが結合したものである。そして,この結合によって,人間の分類体系の高度な発達が達成されたのである。
人間のもつ分類をより複雑にしている現象がさらにある。それは語の意味における意味素性の多面性,または語の意味の多義性と相関している。たとえば,〈スパゲッティ〉は〈めん〉という意味素性をもつだけでなく〈西洋料理〉という意味素性をももっている。そのため,〈日本料理〉〈中華料理〉〈西洋料理〉というような分類を用いるとすれば,〈うどん〉などは〈日本料理〉に含められるが,〈スパゲッティ〉は〈西洋料理〉に含められるであろう。このようにひとつの語はその意味素性,あるいは意味の多義性によってさまざまの分類体系に出現するようになり,その分類体系を複雑にしている。しかし,一方でこのことは人間の分類体系を豊かにしているともいえるであろう。
→名 →認識人類学
執筆者:吉田 集而
個体や事物を数理的な手続を規定して分類するのに用いられる分析法をクラスター分析と総称する。分類された各類はクラスターと呼ばれる。クラスター分析は,クラスター内の個体間の距離を小さくし,異なるクラスター間の距離を大きくするようにクラスターを定める手法である。個体間の距離としては,ユークリッド距離やマハラノビスMahalanobis距離が用いられる。クラスター間の距離を定義する方法としては,各クラスターのメンバーの平均位置(重心)を考え,その間の距離とする方法や,メンバー間の距離の平均や最大,最小を用いる方法がある。クラスター分類法には,クラスター数をあらかじめ想定して最適な分割を行う非階層的方法と,クラスター数を固定せず,対象の階層的分類構造を樹形図dendrogramとして求め,目的に応じて大分類から小分類まで種々利用できるようにする階層的方法とがある。クラスター分析と似てはいるが異質のものに判別分析がある。判別分析では,対象の集合がいくつかの群に分類されており,対象ごとにこれを特徴づけるいくつかの変量の値がすでに与えられていると仮定する。これらの値から,別に与えられた個体がどの群に属するかを,その変量より推定する。これらの分析法は,回帰分析,主成分分析,因子分析などと並んで多変量解析と総称される。
これらの手法は,対象を特徴づける変量が比率尺度ratio scaleや間隔尺度interval scaleと呼ばれる尺度をもつときのみ適用可能である。間隔尺度とは数値の差が意味をもつ尺度(たとえば℃で表した温度)をいい,比率尺度とは絶対原点をもつ間隔尺度(たとえばKで表した温度)をいう。尺度にはこのほかにも,大きさには意味がないが大小関係には意味がある順序尺度ordinal scale(たとえば身長の順位)や,性別,職業のように,数値で表したとしても,その大きさや大小関係には意味がない名義尺度nominal scale(たとえば郵便番号)がある。対象を特徴づける要因が量的な変量としてではなく,順序尺度や名義尺度をもつ質的なデータとして与えられている場合に,数量的評価を与え分類を可能にする手法として,数量化理論の数量化Ⅲ類,Ⅳ類,最小次元解析(SSA:small scale analysis),多次元尺度構成法などがある。これらは,種々の要因についての情報にもとづいて,互いに似ている対象を近くに,似ていないものを遠くに位置づけるように空間的に配置する手法である。数量化Ⅲ類では,要因として各個体の種々のカテゴリーへの反応の仕方が与えられたとき,個体とカテゴリーの両方を数量化する。一方数量化Ⅳ類では,対象のペアごとに親近性が定義されているような対象の集合を,親近性の大きいペアが近くに,小さいペアが遠くになるよう空間に配置する。数量化理論が非計量的要因に対しダミー変数を導入し,ダミー変数の間に線形の関係を仮定するのに対し,最小次元解析や多次元尺度構成法は必ずしも線形性を仮定しない。一方,数量化Ⅱ類は順序尺度や名義尺度をもつ要因をも考慮して判別分析を行う手法である。
多変量解析を用いた分類の応用の一つとしてパターン認識がある。文字や音声などのパターンや,地図や写真などの画像中の特定の対象物が,あらかじめ登録しておいた種々の標準パターンのグループの中のどれに相当するかを決定することをパターン認識という。入力パターンと標準パターンの照合はあらかじめ定められたいくつかの特徴量の類似度を調べることによって行われる。特徴量は多変量解析や数量化法によって定量化される。標準パターンごとに前もって特徴量を求めておく場合と,学習により特徴量を随時調整し直していく場合とがある。パターンの照合は判別分析などにより行う。画像認識の場合には,特徴量抽出を行う前に入力パターンの位置や大きさ,濃淡などを正規化する必要がある。音声認識の場合には,パターンの照合の際に入力音声の時間軸を許容範囲で伸縮させ,時間軸の整合を行う必要がある。文字認識の場合には,特徴量として計量的変量のほかに位相構造的特徴を用いることが多い。
分類はソーティングsortingの訳としても用いられている。ソートとはデータを大小順に並べ換える処理をいう。ソートはコンピューターでデータをあつかう場合の基本的な処理の一つである。任意の順序に並んだn個のデータをソートするのには少なくともlog2n!回の比較が必要であり,データの個数が増加するとその処理時間が急速に増大するため,さまざまなアルゴリズムが考えられ,場合に応じて利用されている。アルゴリズムのおもなものの名称と平均比較回数,最大比較回数,データの格納以外に要するメモリー領域の大きさの近似式を,この順に列挙する。近似式がO(f(n))と表されている場合は,正確な式g(n)が定数cを適当に選ぶことにより,十分に大きなnに対してつねにg(n)<c・f(n)とできることを示す。バブル・ソートbubble sort〈O(n2),O(n2),0〉,クイック・ソートquick sort〈O(n log n),O(n2),O(log n)〉,ヒープ・ソートheap sort〈O(n log n),O(n log n),0〉,ラディックス・ソートradix sort〈O(ω・n),O(ω・n),O(n)(ωは桁数)〉,マージ・ソートmerge sort〈O(n log n),O(n log n),O(n)〉,バイトニック・ソートbitonic sort〈O(n log2n),O(n log2n),0〉。
執筆者:田中 譲
出典 株式会社平凡社「改訂新版 世界大百科事典」改訂新版 世界大百科事典について 情報
Sponsored by ![]()
出典 図書館情報学用語辞典 第4版図書館情報学用語辞典 第5版について 情報
Sponsored by ![]()
出典 (株)ジェリコ・コンサルティング流通用語辞典について 情報
Sponsored by ![]()
出典 ブリタニカ国際大百科事典 小項目事典ブリタニカ国際大百科事典 小項目事典について 情報
Sponsored by ![]()
字通「分」の項目を見る。
出典 平凡社「普及版 字通」普及版 字通について 情報
Sponsored by ![]()
…通常は分類によって立てられる部門を指すが,哲学用語としては,人がものを考え認識するにあたって必ず従わなければならない形式としての最も一般的な概念ないし分類語を意味する。〈範疇(はんちゆう)〉の訳語は《書経》洪範篇の〈洪範九疇〉(〈洪範〉は天地の大法,〈疇〉は田畑を区切るあぜ道)から取って,明治時代西欧哲学の移入時に作られた。…
…ある集団について各個体の属性あるいは形質データにもとづき似たものどうしをいくつかの群(クラスター)にまとめて類型を作り出す分類手法で,統計的多変量解析法の一つ。数値分類法や自動分類法などともいわれる。…
※「分類」について言及している用語解説の一部を掲載しています。
出典|株式会社平凡社「世界大百科事典(旧版)」
Sponsored by ![]()
夏の暑さに体が慣れること。数日から数十日間で起こる短期暑熱順化と、数年または数世代にかけて起こる長期暑熱順化とがある。→寒冷順化[補説]近年では、冷房設備の普及にともない短期暑熱順化が起こりにくくなっ...